[HAI5016] Week 14: Indexing dr. Kingo

Last week we saw some great presentations that highlighted the challenges of non-English interactions with LLMs and introduced us to the key concepts of chunking and indexing. This week, we’ll take a dive into parsing and indexing knowledge from the Dr. Kingo dataset. Using the Azure OpenAI API, we’ll transform the scraped websites into Markdown files to construct a document store. Then, we’ll calculate embeddings and utilize LLamaIndex to store document chunks in a vector database.
Disclaimer: This blog provides instructions and resources for the workshop part of my lectures. It is not a replacement for attending class; it may not include some critical steps and the foundational background of the techniques and methodologies used. The information may become outdated over time as I do not update the instructions after class.
1. Back to your Codespace
To open our workspace in the cloud, we’ll go back to GitHub and open our codespace.
- Go to your repositories on the GitHub website
- Open the
dr-kingorepository Click on the ‘Code’ button and find the codespace you created last week under ‘On current branch’
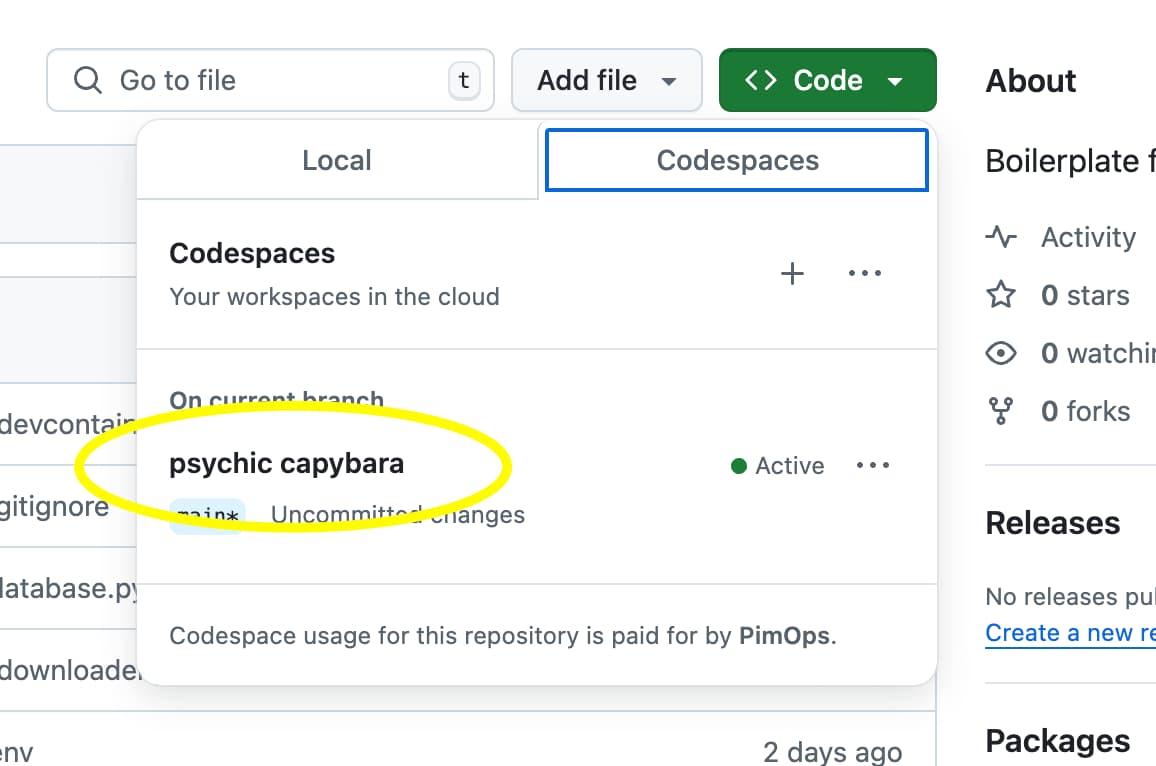
If you don’t see the codespace, you can create a new one by clicking on the ‘Create codespace’ button. Be aware that this will take a little longer because a new container needs to be created and all the dependencies need to be installed.
2. Database and repository updates
I have added and updated some files in the original dr-Kingo repository that you need to pull into your codespace. To do this, open a new terminal in your codespace and run the following commands.
2.1 Update the repository
Check if the pimatskku repository is added as a remote:
1
git remote -vThis should show you the origin and upstream remotes:
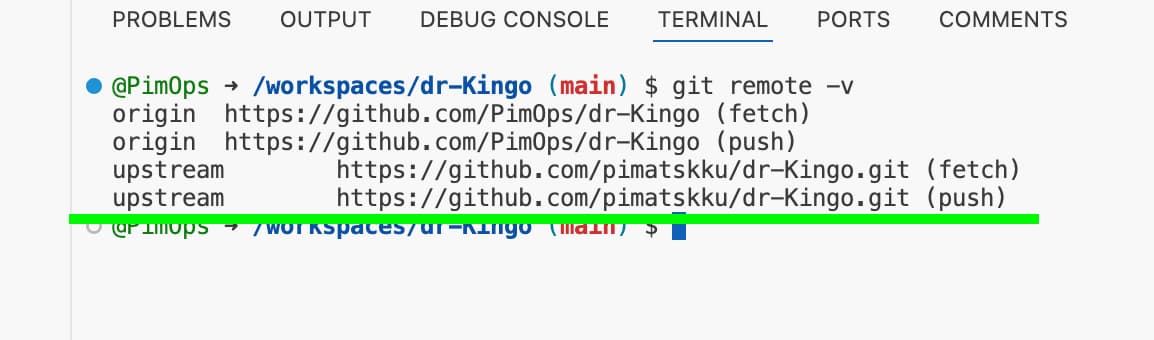
If you don’t see the upstream remote, you can add it with the following command:
git remote add upstream https://github.com/pimatskku/dr-Kingo.git
2.2 Fetch and merge the updates
Fetch the updates from the original repository:
1
git fetch upstream
This will show you the updates that are available to merge.
Merge the updates into your local branch:
1
git merge upstream/main
To resolve conflicts by overwriting your files with the updates, run the command
git merge -X theirs upstream/main. While this approach is not a general best practice, it is acceptable for the purposes of this class.
Now you should have all the updates from the original repository in your codespace.
2.3 Delete the skku_md table
Although this is not best practice, but because I made some changes in the skkuMd class in our code, we are going to delete the skku_md table in the Supabase database. In this table we are going to store the markdown files parsed from the HTML that we have scraped from the SKKU website.
- Open your Supabase dashboard (https://supabase.com/dashboard/) and click on your project name
- In the left navigation bar click on
Table Editor - Find and click on the
skku_mdtable, then click on the three dots on the right side of the table name and selectDelete tablethe table should disappear from the list of tables in the Table Editor
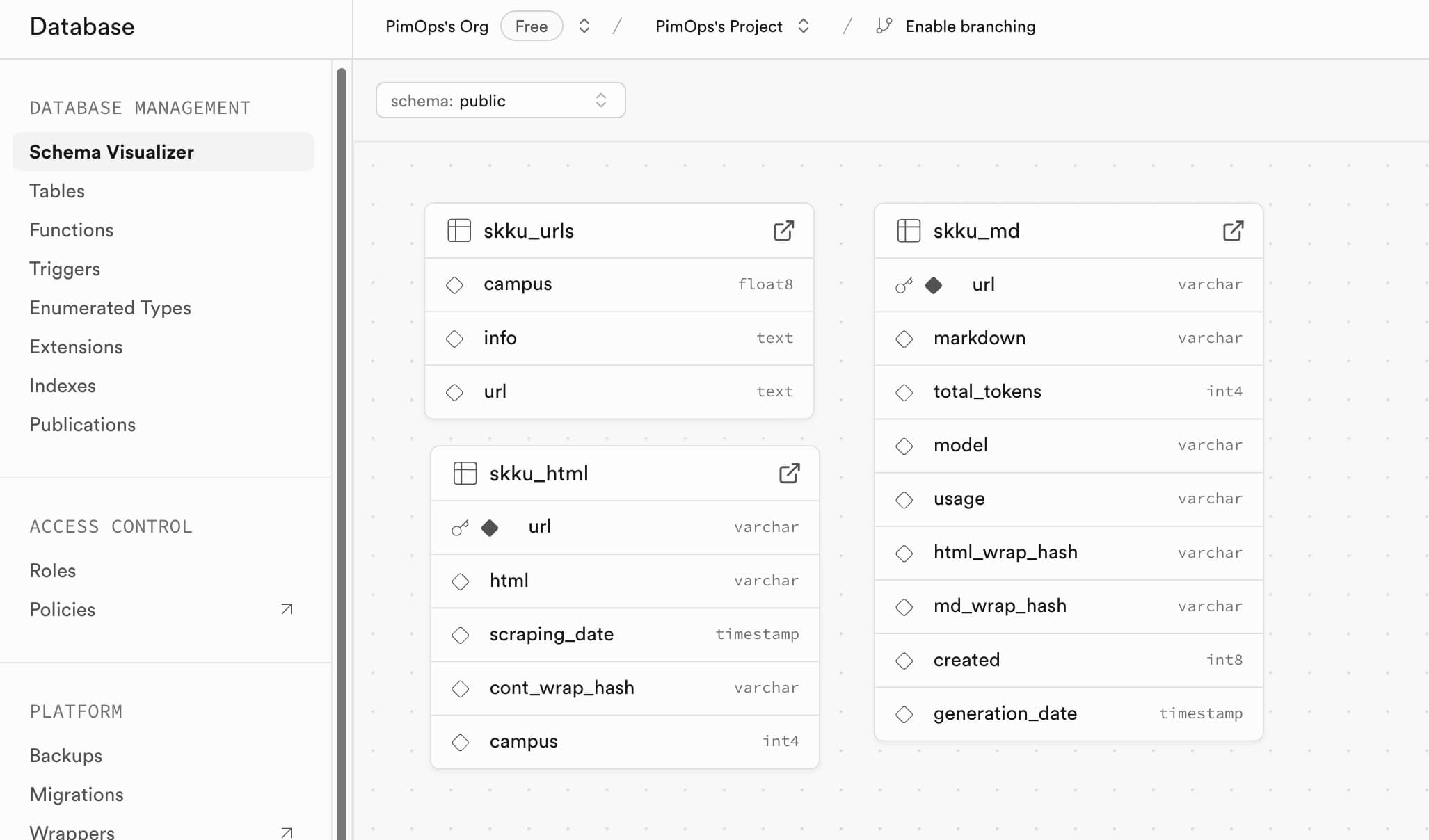
2.4 Run the database.py script again
To recreate the skku_md table in the Supabase database, run the database.py script again. This script creates non-existing tables based on the ORM classes that we use to interact with the tables in our database.
To check if all the tables in our database are created, check the ‘Database’ tab in the Supabase navigation bar:
3. Add Azure OpenAI API information to your .env file
Next, we need to collect the information of the Azure OpenAI API endpoint and keys to interact with the Azure OpenAI API. The Azure OpenAI API is a little different from the standard OpenAI API, so we need to collect a bit more information than you might be used to.
In our Codespace, open the
.envfile, and add the following variables at the bottom of the file:1 2 3 4 5 6
AZURE_OPENAI_API_KEY= AZURE_OPENAI_ENDPOINT= AZURE_GENERATION_MODEL= AZURE_GENERATION_MODEL_VERSION= AZURE_EMBEDDING_MODEL=
3.1 Get your Azure OpenAI API key and Endpoint
In the Azure portal go to Azure OpenAI Service > your project > Resource Management > Keys and Endpoint to get your API keys and endpoint
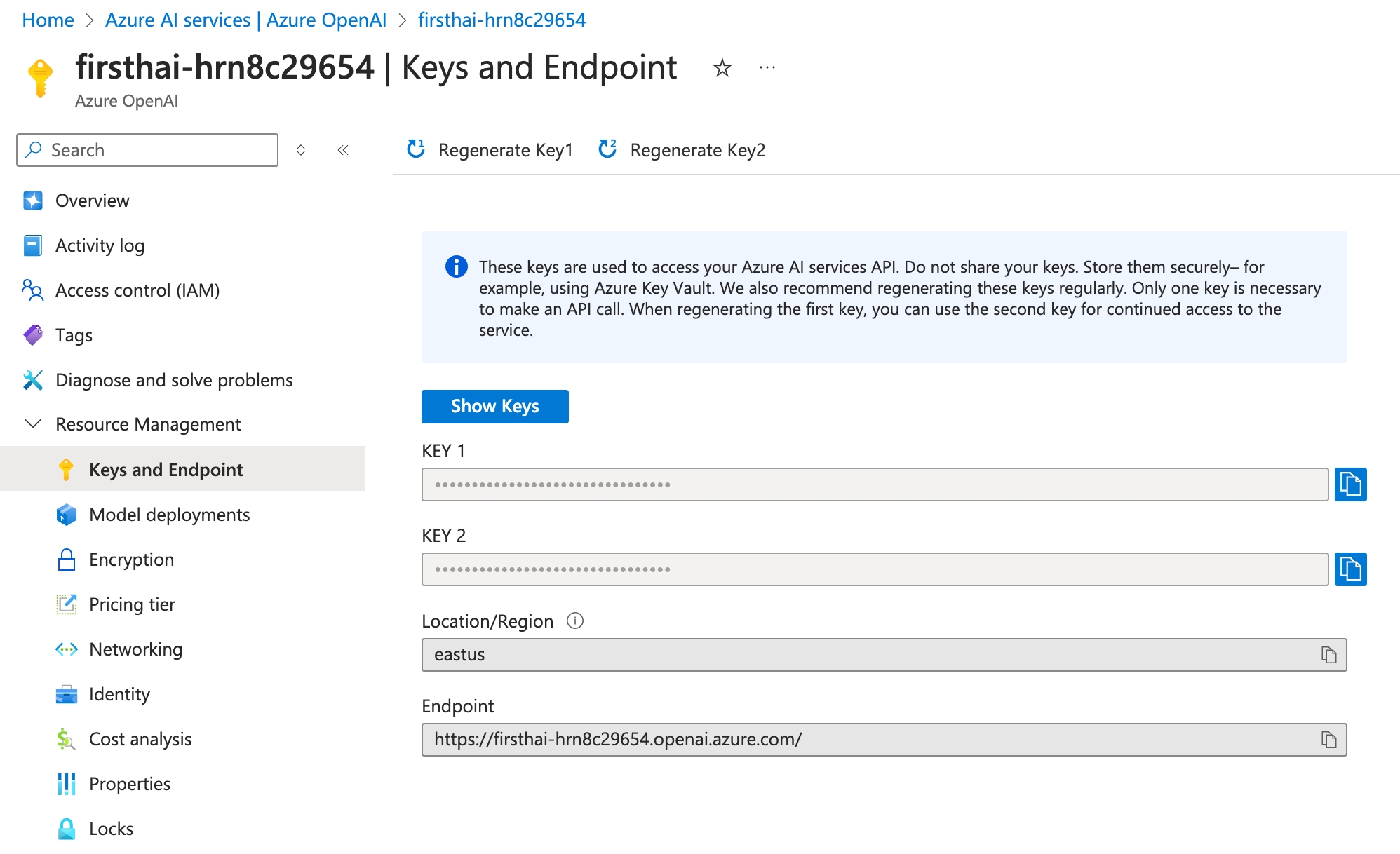
- Click on next to one of the keys to copy it, and paste it behind
AZURE_OPENAI_API_KEY= - Copy the Endpoint location and paste it behind
AZURE_OPENAI_ENDPOINT=
3.2 Check and insert your deployed models
Throughout the semester we have deployed and asked for a quota increase for several models. Make sure you select a model that is deployed and has a higher quota than the standard 1K TPM. More information on how to deploy models can be found in the post of Week 8.
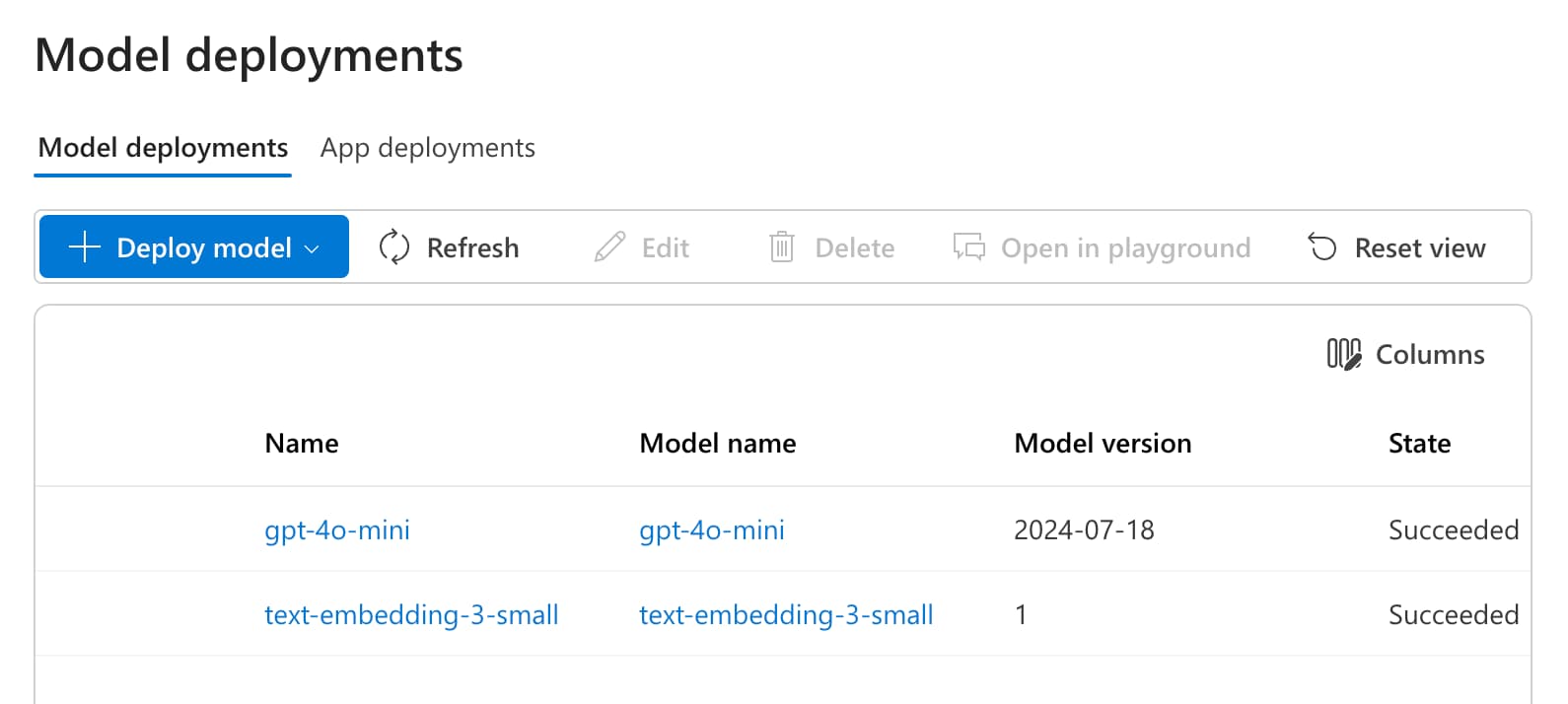
Open Azure OpenAI Studio and check the models that are deployed
Depending or your model deployments, fill the AZURE_GENERATION_MODEL and
AZURE_EMBEDDING_MODELvariables with the names of the models you have deployed. For example, in my setup, it will look like this:1 2 3
AZURE_GENERATION_MODEL=gpt-4o-mini AZURE_GENERATION_MODEL_VERSION=2024-08-01-preview AZURE_EMBEDDING_MODEL=text-embedding-3-small
If you deployed gpt-4o, the parsing of the markdown files will take a little longer than with the gpt-4o-mini model. This is because the gpt-4o model is a larger and more expensive model. And if you deployed gpt-35-turbo-16k, you might need to adjust the code by removing chat from
client.chat.completions.createand replace themessagesparameter withprompt(no array).
4. Parsing the SKKU website HTML files to Markdown
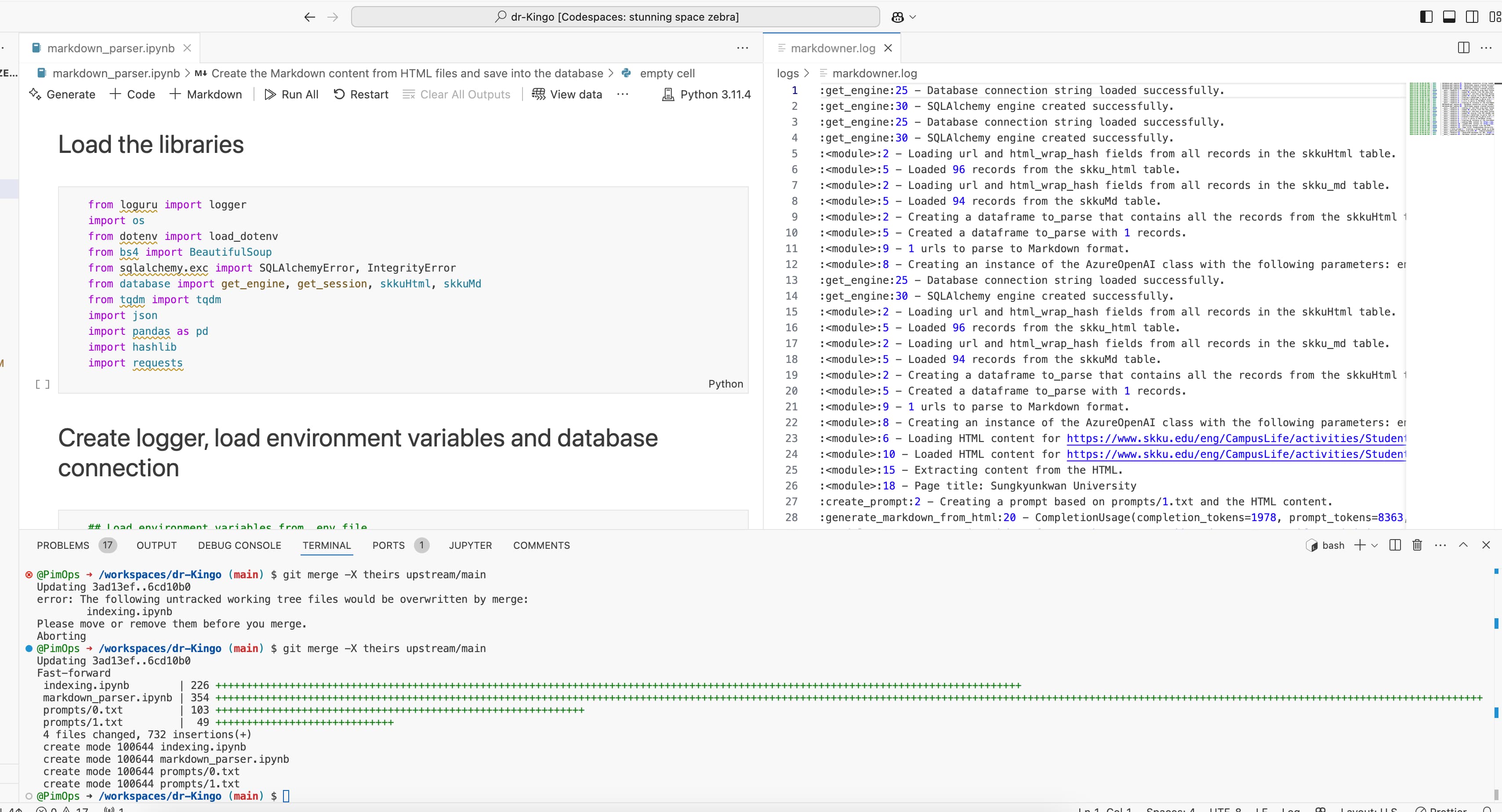
The markdown_parser.ipynb notebook will parse the HTML files that we have scraped from the SKKU website and convert them into Markdown format. Then, the script will save the parsed markdown files into the skku_md table in our Supabase database.
- Let’s explore the notebook together and run the script to parse the HTML files.
While the script is running, let’s enjoy another student presentation.
- After the presentation, let’s examine the parsed markdown files in the
skku_mdtable in our Supabase database.
We can export the Jupyter Notebook into a Python script so we can run it easily in the future.
Progress, results and errors can be found in the
logs/markdown_parser.logfile.
5. Indexing the parsed Markdown files
To index the parsed markdown files, we will use the llamaindex package. This package will take care of chunking of the markdown files, calculating the embeddings, and storing the embeddings in a vector store.
- Let’s open the
indexing.ipynbnotebook and run the script to index the markdown files.
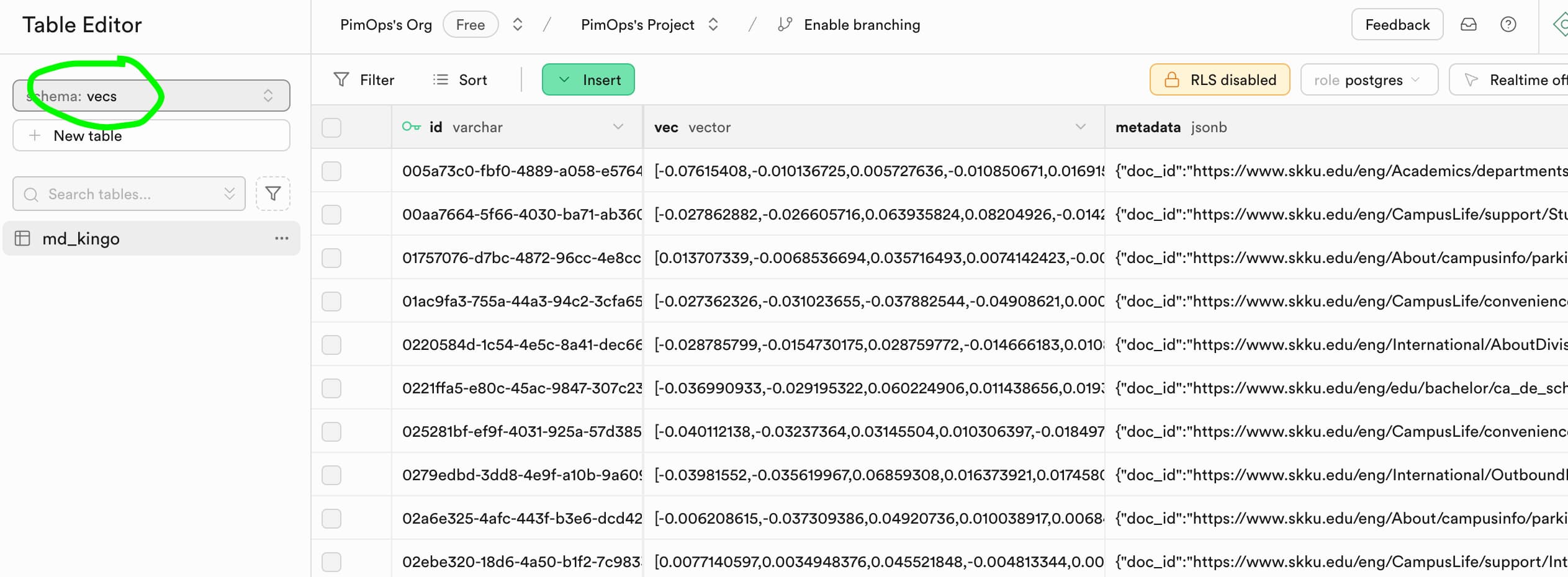
5.1 Check the vector store
After the indexing is done, we can check the vector store in the Supabase dashboard. In the left navigation bar, click on Table Editor and find the vecs schema. Here you can see the md_kingo table that contains the embeddings for the nodes of our markdown files.
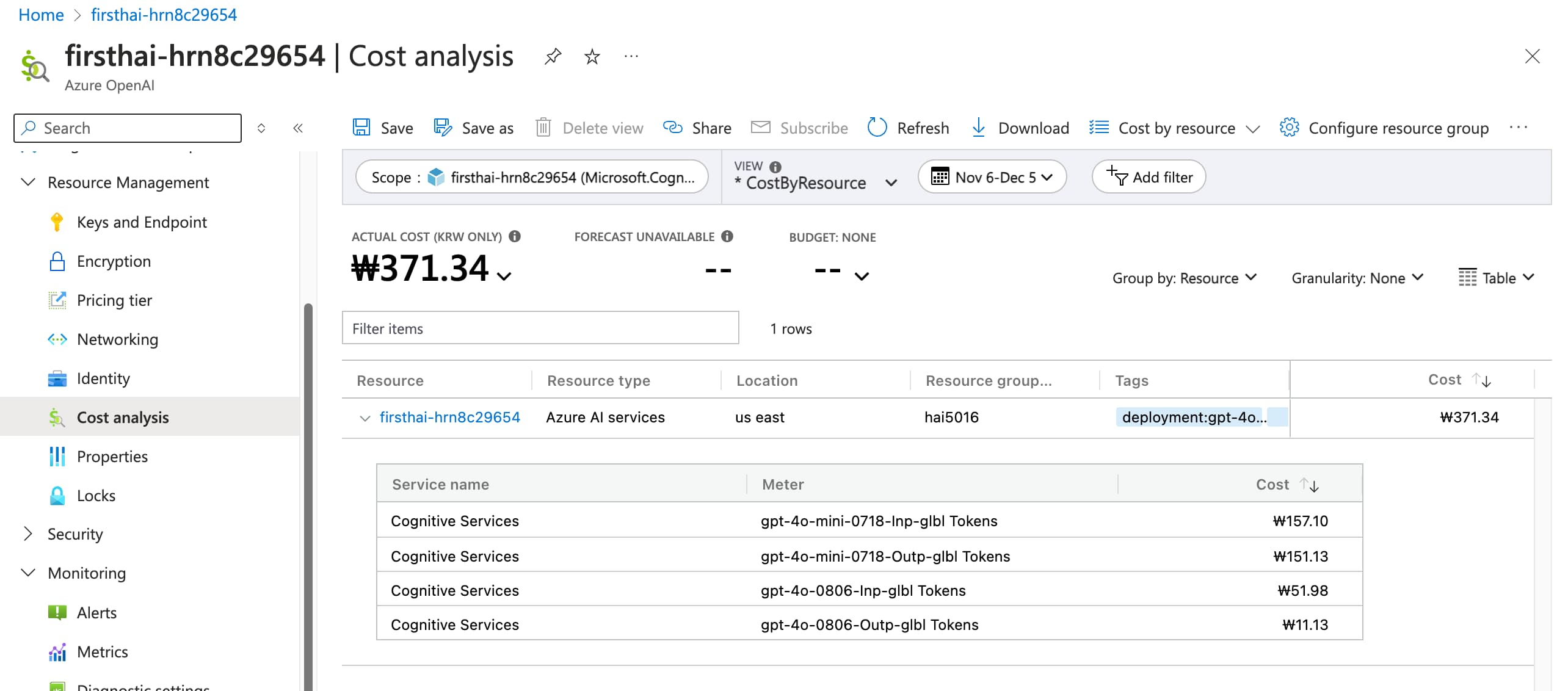
6. Bonus: Check the cost of parsing and indexing
To check the cost of your Azure OpenAI API usage, you can go to the Azure portal and check the usage of your Azure OpenAI service.
- In the Azure portal, find your Azure OpenAI resource
- In the left navigation bar, find
Cost AnalysisunderResource Managementand click on it To specify the costs per model, click on the view
Cost by resource