[HAI5016] Week 10: Seoul Bike Sharing Demand Prediction with Copilot

Today we’ll continue from where we left off last week. We will use the Seoul Bike Sharing dataset from Kaggle to predict the demand for shared bikes in Seoul based based on various environmental factors. We will use the Copilot AI to help us write the code for this prediction task.
Disclaimer: This blog provides instructions and resources for the workshop part of my lectures. It is not a replacement for attending class; it may not include some critical steps and the foundational background of the techniques and methodologies used. The information may become outdated over time as I do not update the instructions after class.
1. Upgrade our Markdown flow with markdownlint
To improve our Markdown writing skills, we will install the markdownlint extension in VS Code. This extension will help us write better Markdown by providing suggestions and warnings for common Markdown writing mistakes.
- Install the markdownlint extension in VS Code
2. Create context for Copilot in the README.md file
We will create a context for Copilot in the README.md file. This context will help Copilot understand the task we are working on and provide more relevant code suggestions. We will add the following information to the README.md file.
- Open the
README.mdfile in VS Code Copy and paste the following context information into the
README.mdfile above the existing dataset description:1 2 3 4 5 6 7 8 9 10 11 12 13 14
Project Overview: Predicting Demand for Seoul's Bike Sharing Program Problem Statement Bike-sharing systems provide eco-friendly, short-term access to bicycles and are becoming increasingly popular in urban areas. They contribute to reducing traffic congestion, promoting healthier lifestyles, and supporting sustainable urban transportation (Sathishkumar et al., 2020). Seoul's bike-sharing system has expanded significantly, creating a need for precise demand forecasting to ensure that bike availability matches user demand. Accurate demand prediction is vital to meet the needs of Seoul’s growing bike-sharing user base. By analyzing patterns in historical data, we aim to develop predictive models that incorporate factors influencing rental demand, including weather, time, and other environmental variables. The continuous expansion of bike-sharing systems necessitates sophisticated data-driven insights to maintain an efficient, user-responsive service. Influence of Environmental Factors Natural environmental factors, such as temperature, rainfall, humidity, and wind speed, have a considerable impact on bike rental patterns (Eren and Uz, 2020). For instance, rainfall and high noon temperatures can decrease bike usage, as found in studies of both Seoul and international locations like Hamilton, Canada (Zhu et al., 2020; Scott and Ciuro, 2019). These findings underscore the role of weather as a key predictor in understanding and forecasting bike-sharing demand. Prior Research and Methodology Researchers have experimented with a variety of statistical and machine learning models to predict demand. Studies show that techniques such as Gradient Boosting and Cubist regression yield high R-squared values, indicating strong predictive capabilities for complex, weather-influenced patterns (Sathishkumar et al., 2020; Ve and Cho, 2020). Additionally, Kashyap and Swastik (2021) used similar datasets to our project, employing correlation analysis to understand the relationship between weather and bike rental counts. Although demand prediction models for human behavior typically result in lower R-squared values, these insights remain crucial for practical applications. Business Context Meeting the fluctuating demand for rental bikes is central to the success of Seoul's bike-sharing system. An undersupply can lead to missed opportunities and decreased customer satisfaction, while an oversupply can result in resource waste due to maintenance and storage costs. Thus, effective demand forecasting is essential for both operational efficiency and user satisfaction. By ensuring bikes are available when and where they are needed, this project supports Seoul’s efforts to enhance accessibility, promote eco-friendly transport, and create a seamless bike-sharing experience.
- Improve the markup of the text using VS Code’s Markdown suggestions (
Ctrl+Space) and the preview feature to ensure the text is formatted correctly. After installing the markdownlint extension, any lines that violate one of markdownlint’s rules will trigger a Warning in the editor. - After marking up the text, also check out the various methods to navigate through your document structures in VS Code:
- Use the
Ctrl+Shift+Okeyboard shortcut to open the Outline view, which shows the structure of your document - Click on the current header in the breadcrumbs to see a list of all headers in the document
- Check out the
OUTLINEsection in the Explorer view to see a list of all headers in the document - Use
Ctrl+Tto search through headers across all Markdown files in the current workspace
- Use the
Save the file but keep it opened in VS Code because “Having related files open in VS Code while using Copilot helps set this context and lets the Copilot see a bigger picture of your project” (source)
One way to create context for the assisting LLM is to have related files open in your workspace. Another way is to use Top Level Comments. Just like you would provide a high-level introduction to a colleauge to explain your code, writing this in a comment at the top of your file can help the LLM understand the context of your code (source).
- Commit and push the changes to your repository
3. Get the Seoul Bike Sharing dataset from Kaggle
- Create a new python file called
kaggledl.py - Go to https://www.kaggle.com/datasets/saurabhshahane/seoul-bike-sharing-demand-prediction
- Click on the “Download” button to open the download menu
- Select download via
cURLand copy the URL of the dataset Go back to the newly created python file, press ctrl+i and ask copilot to download the dataset using the URL you copied and unzip it into the data folder. For example:
1
Download the file from https://www.kaggle.com/api/v1/datasets/download/saurabhshahane/seoul-bike-sharing-demand-prediction and unzip in into a folder called data
- Run the script and use copilot to solve any issues that you may encounter
Press
crtl+alt+ito open Copilot chat and ask it to add logging using the loguru package and log to a file called download_dataset.log. For example:1
Add logging to the download_dataset.py file using the loguru package and log to a file called download_dataset.log
- Click the
Apply in editorbutton, check the new code generated by Copilot (highlighted in green) and accept the changes if you are satisfied with them - Run the script to test the logging feature (check out your brand new log file
download_dataset.log) - Commit and push the changes to your repository, but before that add the data folder to the
.gitignorefile to avoid uploading the dataset to GitHub
4. Beat SPSS with VS Code, Jupyter, and Copilot
On the internet I found the following article: Applying Multi-Linear Regression on Seoul Bike Sharing Demand using IBM SPSS Statistics by Ngu Hui En. The author used IBM SPSS Statistics and applied a stepwise multi-linear regression (MLR) model to predict bike-sharing demand in Seoul based on environmental factors like temperature, humidity, wind speed, and rainfall. As I mentioned during class, I think that SPSS is a bit outdated and that we can achieve similar results way faster using Python, Jupyter, and Copilot. Let’s try!
Create a new Jupyter Notebook using Copilot
First, we will create a new Jupyter Notebook using Copilot. Copilot will help us write the code for the notebook based on the context we provided in the README.md file.
- Open a new the Copilot chat by clicking on the Copilot icon next to the command palette in the top of VS Code or pressing
Crtl+Alt+I. Click the+icon if anothe prompt is already open. Start your prompt with
/newNotebookand ask Copilot to generate a new Jupyter Notebook based on the context in your workspace. For example:1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
Open a new Notebook with the to use a stepwise multi linear regression (MLR) approach like in IBM SPSS to distinguish characteristics that significantly account for the variance in bike-sharing system demand: 1. To discover the relationship between temperature and hourly counts of rented bikes. 2. To identify whether the wind speed exerts a significant impact on the counts of rented bikes at each hour. 3. To determine whether rainfall have any effects on counts of rented bikes on an I want to test the following hypothesis: 1 Temperature H0: Temperature has no significant impact on Seoul bike-sharing demand H1: Temperature has a significant impact on Seoul bike-sharing demand 2. Solar radiation H0: Solar radiation does not influence bike-sharing demand. H1: Solar radiation significantly affects bike-sharing demand. 3. Rainfall H0: Rainfall does not impact bike-sharing demand in Seoul. H1: Rainfall impacts bike-sharing demand in Seoul. The dataset is located at data\SeoulBikeData.csv and log every step using the loguru package in a file called demand_prediction.log
Copilot will surggest and outline to generate a new Jupyter Notebook based on the context provided in the README.md file:
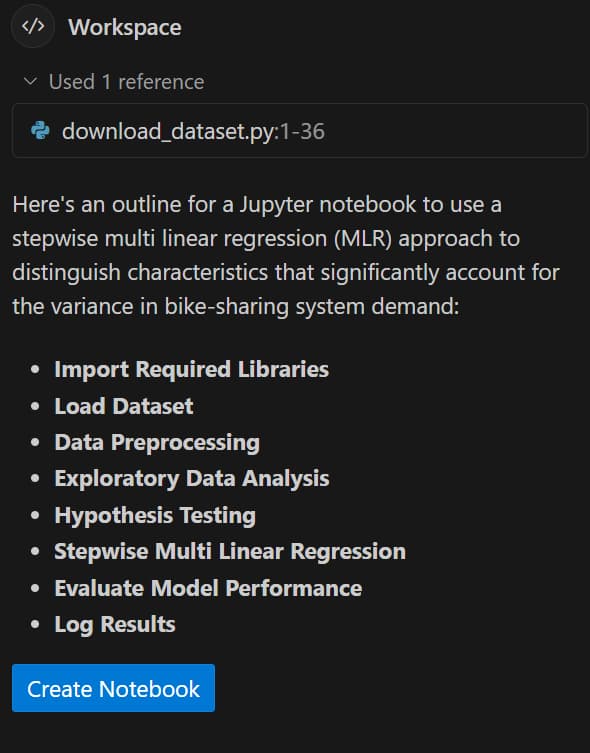
- Click on
Create Notebookto generate the new Jupyter Notebook - Wait and see how Copilot creates the new Jupyter Notebook based on the context provided
- When finished, save the notebook in your project folder and name it
demand-prediction.ipynb - Commit and push the changes to your repository
- Explore your Notebook, run the cells to see the results, solve any issues that you may encounter using Copilot and add functionality to your needs
Disclaimer: I had help from GitHub’s Copilot to improve the writings of this tutorial.
Sources and References
I used the following sources and references to create this post:
- Seoul Bike Sharing Demand Prediction
- yomibankole01/Seoul_BikeSharingDemand_Prediction: The project focuses on utilizing regression techniques on historical data to predict the demand for the bike-sharing program in Seoul.
- Navneet2409/bike-sharing-demand-prediction
- Applying Multi-Linear Regression on Seoul Bike Sharing Demand using IBM SPSS Statistics by Ngu Hui En Medium
- markdownlint - Visual Studio Marketplace
- Full article: A rule-based model for Seoul Bike sharing demand prediction using weather data
- Project Title: Seoul Bike Sharing Demand Prediction
Which in their turn used the following academic sources:
- Sathishkumar, R., Sivakumar, P., & Sivakumar, S. (2020). A review on bike sharing system using machine learning algorithms. International Journal of Scientific & Technology Research, 9(3), 1-5.
- Eren, O., & Uz, M. (2020). Predicting bike rental demand using machine learning algorithms. Journal of Applied Statistics, 47(9), 1601-1616.
- Zhu, Y., Zhang, Y., & Liu, Y. (2020). Bike-sharing demand prediction with weather data. In 2020 IEEE International Conference on Systems
- Scott, D. M., & Ciuro, A. (2019). The impact of weather on bike-sharing demand: A case study of Hamilton, Canada. Journal of Transport Geography, 74, 1-10.
- Ve, A. S., & Cho, S. (2020). Bike-sharing demand prediction using machine learning algorithms. In 2020 IEEE International Conference on Systems
- Kashyap, A., & Swastik, S. (2021). Predicting bike rental demand using machine learning algorithms. Journal of Applied Statistics, 47(9), 1601-1616.